目录中仅有 17.7% 的技能足够热门而接受了安全评级,在已评级的技能中,每 32 个就有 1 个是不安全的,风险主要集中在长尾部分——此外还存在一种新的面向智能体的攻击面。

我们对 117,854 个人工智能智能体技能进行了安全评级。以下是我们的发现。 | 智能体技能中心
仅有 17.7% 的技能足够热门而接受了评级。在已评级的技能中,每 32 个就有 1 个是不安全的。风险存在于长尾部分。
令人不安的并非那些不安全的技能,而是真正经过检查的技能寥寥无几。
安装一个人工智能智能体技能或模型上下文协议服务器,意味着将你的命令行环境、环境变量,以及日益重要的智能体自身配置和内存,交给不受信任的代码。发现技能很容易——有数以万计的技能可供选择。但要判断你找到的那个技能运行起来是否安全,却并非易事。
因此,我们扫描了整个目录。以下是真实的情况。
📄 这是一篇交叉发布的文章。权威版本(含图表):agentskillshub.top/blog/securing-117k-ai-skills
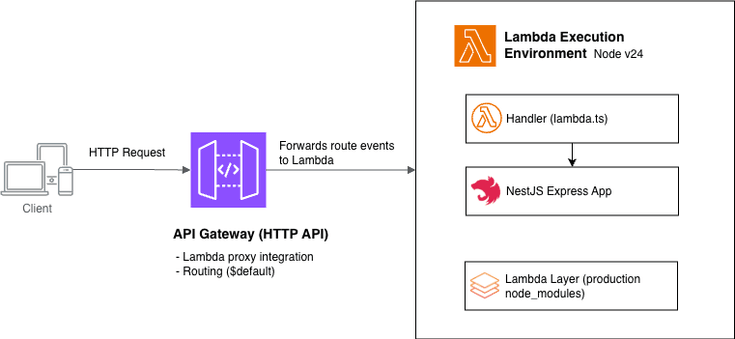
我们如何进行扫描
我们使用了一个基于规则的扫描器,其设计灵感来源于慢雾科技的智能体安全框架及其定义的 11 类危险信号。该扫描器对每个技能的自述文件和代码进行静态检查,寻找具体的模式: outbound 数据窃取(curl -d $(...))、凭证收集(env | grep -i token)、读取 .env / .ssh / .aws 文件、curl | sh 安装脚本、权限提升、持久化以及秘密信息窃取的组合行为。每个技能都会获得一个评级——安全 / 谨慎 / 不安全 / 拒绝——以及触发的具体危险标志。没有自述文件或因太新而无法获取的技能则标记为未知。
这故意被设计为第一道防线:它捕捉的是模式,而非意图。在 11.7 万的规模下,模式层是让整个目录具备可审计性的关键。
发现一 —— 82% 的目录内容从未被评级
在117,854 个已索引的技能中,只有20,853 个(17.7%)达到了五星标准——即技能足够热门,值得进行评级的门槛。其余约 97,000 个技能实际上未经过审计。
“我们拥有 11.7 万个技能”并不是一项优势。真正重要的数字是你可以实际信任的技能数量,而对于长尾部分,诚实的回答是:没有人查看过。
发现二 —— 在已评级的技能中,每 1
免责声明:本文内容来自互联网,该文观点不代表本站观点。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请到页面底部单击反馈,一经查实,本站将立刻删除。
免责声明:本文内容来自互联网,该文观点不代表本站观点。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请到页面底部单击反馈,一经查实,本站将立刻删除。